[FR] Langage assembleur sur ez80 - Tutoriel
Guide du langage assembleur pour calculatrices à processeur ez80
TI-83 Premium CE & TI84+CE
Version: 0.0
TI-83 Premium CE & TI84+CE
Version: 0.0
* * *
I / Préparation
1 - L'édition d'un programme
Il existe à l'heure actuelle de nombreuses plateformes pour l'édition. Vous pouvez utiliser n'importe quel éditeur de texte, du Bloc-notes, à WordPad en passant bien sûr par Notepad++. Notepad++ a l'avantage de pouvoir définir un highlight automatique des commandes ASM.
Créez un document texte et changez son extension en .z80, .ez80 ou .asm, l'extension n'ayant que peu d'importance. (Il faut seulement que ce fichier soit reconnu et ouvert par votre OS avec le bon programme que vous utilisez). Par la suite, j'utiliserai l'extension .ez80.
2 - L'assemblage
Pour créer le programme que vous pourrez par la suite envoyer sur la calculatrice, il faut effectuer une étape consistant à transformer ce que vous avez écrit en code compréhensible par le processeur de la calculatrice. Il s'agit de l'assemblage. Rassurez vous, cette étape n'est pas à faire à la main, mais un programme appelé assembleur va faire ça pour nous.
Le programme s'appelle SPASM, et est téléchargeable gratuitement ici.
Cependant, nous avons aussi besoin d'autres éléments. La plupart des programmes assembleurs reposent sur des fonctions toutes faites présentes dans l'OS de votre calculatrice, ou encore sur des nombres constants qui ont une signification particulière. Comme nous n'allons pas apprendre tout ces nombres par cœur, nous pouvons demander au compilateur de créer des noms de fonctions bien plus compréhensibles par un être humain. Le fichier qui permet d'effectuer ceci s'appelle un fichier include.
Vous pouvez trouver le fichier include correspondant à votre calculatrice ici.
À noter :
Ce fichier n'est pas fourni par TI. Les valeurs qui y sont présentes ont été trouvées par des utilisateurs chevronnés. Ceci n'exclut donc pas des erreurs (même si jusque là, aucune n'a été découverte), et surtout il n'est pas complet. Veillez à le mettre à jour de temps en temps.
Ce fichier n'est pas fourni par TI. Les valeurs qui y sont présentes ont été trouvées par des utilisateurs chevronnés. Ceci n'exclut donc pas des erreurs (même si jusque là, aucune n'a été découverte), et surtout il n'est pas complet. Veillez à le mettre à jour de temps en temps.
Il n'est pas nécessaire pour l'instant de tenter de comprendre ce fichier, je vous assure que par la suite il vous semblera simple ")
Créez un nouveau fichier dans votre répertoire dédié à la programmation assembleur et appelez le
ti83pce.inc. Copiez-collez le contenu du lien ci-dessus et enregistrez : votre fichier est prêt à l'emploi.Une fois ceci fait, nous allons voir comment compiler le programme avec SPASM.
Sous windows, il faut créer un fichier de commande .bat dans le même répertoire que votre fichier .ez80, votre .inc et spasm64.exe:
- Créez un fichier texte
- Copiez les deux lignes suivantes :
spasm64 -E exemple.ez80 TEST.8xpetpause - Fichier, Enregistrer sous...
- Renommez le fichier en "build.bat"
- Et enregistrez le tout.
Les deux lignes signifient d'exécuter le programme spasm64 sur le fichier "exemple.ez80" (nom que vous pouvez changer), et de créer le programme résultant "TEST.8xp". L'option -E permet de compiler pour le processeur ez80 de la TI-83PCE. Une pause est mise à la fin pour que vous puissiez voir les erreurs (présentes ou non) lors de la compilation.
3 - Transfert et émulation
Une fois un .8xp obtenu vous pouvez soit l'envoyer sur votre calculatrice (en suivant ce tuto ou utiliser un émulateur.)
Il est conseillé d'utiliser l'émulateur en premier lieu car il est très facile de faire une erreur en assembleur, ce qui peut conduire à un RAM clear. Sur l'émulateur vous pourrez en plus débugger vos programmes directement avec des fonctions telles que l'exécution ligne par ligne, avec une visualisation de la mémoire en temps réel.
Voyons donc comment utiliser l'émulateur.
Tout d'abord, allez le télécharger ici : http://jacobly.com/CEmu/master/latest/ Ce lien est régulièrement mis à jour, donc n'hésitez pas à aller le retélécharger de temps en temps.
Au premier lancement, il demande une ROM. Vous pouvez obtenir une ROM à partir de votre calculatrice en suivant la procédure suivante :
- Sélectionnez "Create a ROM image from a real calculator" puis "continue"
- Puis "Save Programme" donnez le nom que vous voulez .
- "Enregistrer" vous pouvez mettre le nom que vous voulez .
- Envoyez le programme sur la calculatrice
- Exécutez le programme "DUMP" avec "Asm(" trouvable dans le catalogue.
- Maintenant en réactualisant "Ti Connect" il faut récupérer les "AppVar" de "ROMData0" à la "ROMDataK" et les copier sur l'ordinateur (je vous conseille de les copier dans un sous dossier), vous devez en obtenir 12. Vous pouvez les supprimer de votre calculatrice.
- De retour sur CEmu Setup, choisissez "Selects Segments ..." et là vous sélectionnez toutes les "ROMData" qui ont été copiées de la calculatrice.
- "Browse..." vous mettez un nom et vous l'enregistrez.
Votre ROM a maintenant été créée. La suite du setup est plutôt simple, vous pouvez regarder toute les options disponibles de l'émulateur. Ce que nous allons utiliser majoritairement avec est l'onglet "debbuger" et "memory".
Une ROM est strictement personnelle et le partage de la ROM sur internet est illégal, alors ne la mettez pas en ligne !
4 - Hello World
Bon maintenant vous allez compiler et exécuter votre premier programme, le classique hello world
- Code: Select all
#include "ti83pce.inc"
.assume ADL=1
.db tExtTok,tAsm84CeCmp
.org userMem
call _ClrScrnFull
ld hl, $04 \ ld (curRow),hl
ld hl, $06 \ ld (curCol),hl
ld hl,Text
call _PutS
call _GetKey
call _ClrScrnFull
ret
text:
.db "Hello world !",0
Expliquons donc le code pas à pas
La première ligne
#include "ti83pce.inc permet d'inclure dans la compilation votre fichier .inc précédemment copié. Si vous vous en souvenez, il permet de faire le lien entre des listes de nombres et un texte particulier. Comme nous allons le voir par la suite, il est particulièrement utile pour ce programme..assume ADL=1 est une instruction destinée au compilateur pour signifier que le CPU est bien en mode ADL (adresse Long), soit en mode 24 bits, dans lequel nous allons travailler. .db tExtTok,tAsm84CeCmp permet de signifier à l'OS qu'il ne s'agît pas d'un programme TI-Basic mais bien d'un programme assembleur, nécessitant Asm( pour être exécuté..org userMem indique au compilateur quelle est l'adresse initiale dans la mémoire du programme. L'OS copie le programme en userMem lorsqu'il est exécuté, donc tous les programmes assembleurs commencent ici.Ces quatre premières lignes sont appelées header du programme. Elles sont essentielles au fonctionnement de ce dernier et doivent toujours être présentes.
- Code: Select all
call _ClrScrnFull
ld hl, $04 \ ld (curRow),hl
ld hl, $06 \ ld (curCol),hl
ld hl,Text
call _PutS
call _GetKey
call _ClrScrnFull
Ceci est le corps de votre programme. Sans rentrer dans les détails, il appelle différentes fonctions système de la calculatrice afin d'afficher le fameux Hello World. Nous pouvons ici voir la puissance du fichier include : au lieu de devoir mettre l'adresse, c'est à dire la valeur littérale, des différents appels à l'OS, nous pouvons simplement mettre un nom bien plus facile à retenir.
ret Permet de retourner à l'OS et finit le programme.- Code: Select all
text:
.db "Hello world !",0
Ceci est encore une instruction au compilateur. Il permet d'inclure dans le programme des octets de données, ici sous forme de chaîne de caractères, qui sera par la suite utilisable par le programme à l'aide du label "text:". Nous vous expliquerons tout ceci plus en détail dans le chapitre sur la mémoire.
Il ne vous reste plus qu'à compiler votre programme à l'aide du fichier .bat et envoyer le programme sur l'émulateur ou votre calculatrice.
Vous obtenez le résultat suivant :
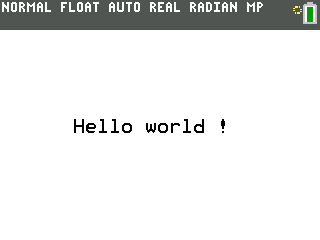
Vérifiez que le compilateur ne revoie pas d'erreurs. Si c'est le cas vérifiez que le .inc est bien dans le bon répertoire, de même que spasm64, et votre fichier exemple.ez80. Un programme qui a renvoyé des erreurs à la compilation ne fonctionnera sans doute pas.
Vous connaissez donc maintenant la structure générale d'un (petit) programme assembleur. Apprenons donc maintenant à le remplir !
* * *
II / Le zilog ez80
1 - Les registres
Les registres sont de petites zones de mémoire présentes directement dans la puce du processeur. Le processeur effectue toutes ses opérations à l'aide de ces registres qui ne peuvent qu'enregistrer une valeur, dont la fonction et la taille dépend du registre.
Nous pouvons distinguer plusieurs classes de registres :
- Les registres de travail. C'est ceux que vous utiliserez le plus souvent.
- Les registres d'index. Très puissants, ils permettent de récupérer des données en mémoire très facilement.
- Les registres de contrôle. Le processeur utilise ces registres pour diverses opérations, ils sont parfois réduit à l'état d'un simple bit.
Les registres sont en général des zones de mémoire de 8bits. Cependant, le ez80 permet de combiner ces zones pour former des zones de 24 bits. Il est cependant à noter que la combinaison est fixe, et que les 8bits les plus supérieurs (ou msb) du registre ne peuvent pas être accédés. Ceci est un ancien artefact du jeu de données du z80 (le prédécesseur du ez80), qui travaillait sur des registres 8 bits & combinés en 16 bits. Il est aussi à noter que certains registres peuvent effectuer des actions particulières que d'autres ne peuvent pas.
Registres CPU de travail
Registres individuels 8 bits
| Registre | Utilisation |
| A | Accumulateur, il est le registre opérande et résultat des opérations mathématiques sur 8 bits |
| F | flags. Ce registre ne peut pas être directement lu/écrit. Il sert à enregistrer des feedbacks des instructions |
| L | utilisateur défini |
| H | utilisateur défini |
| L | utilisateur défini |
| D | utilisateur défini |
| E | utilisateur défini |
| B | utilisateur défini |
| C | utilisateur défini |
Registres combinés 24 bits
Il est à noter que ces registres proviennent de la combinaison des registres 8 bits. Une modification des registres 8 bits entraînera une modification des registres 24 bits. Ainsi, pour le registre HL l'octet de poids faible correspond au registre 8 bits L tandis que l'octet de poids moyen correspond au registre H. Il en est de même pour les autres registres. L'octet de poids fort n'a pas d'existence propre en tant que registre 8 bits, mais possède le nom de HLU, DLU ou BLU.
| Registre | Utilisation |
| HL | Accumulateur 24 bits, il est le registre opérande et résultat des opérations mathématiques sur 24 bits. Il peut aussi servir à indexer des données en mémoire |
| DE | Destination, mais surtout utilisateur défini. Il est utilisé par certaines instructions comme le registre de destination de copie. Il peut aussi servir à indexer des données, mais avec moins de possibilités que HL |
| BC | Byte Counter, mais surtout utilisateur défini. Il est utilisé par certaines instructions comme un compteur. Il peut aussi servir à indexer des données, mais avec moins de possibilités que HL |
Registres CPU de contrôle
| Registre | Utilisation |
| SPL | StackPointerLong, est un pointeur vers le sommet du stack. Il peut dans certains cas être utilisé comme un registre 24 bits de travail |
| PC | ProgramCounter, est un pointeur vers l'instruction actuellement exécutée. Certaines instructions peuvent le modifier |
| I | Interrupt, est un registre utilisé dans le cadre des interruptions. C'est un registre 16 bits |
| MBASE | MemoryBASE, est un registre utilisé dans le cadre d'exécution de code en mode z80, nous en parlerons à la toute fin de ce tutoriel |
| R | Refresh, est un compteur du nombre d'instructions fetchées par le processeur, très rarement utilisé |
| ADL | ADL est un bit indiquant que le mode dans lequel le processeur travaille (z80/ez80) |
| MADL | MADL est un bit indiquant que le processeur travaille dans un mode mixé z80&ez80 |
| IEF1 | IEF1 est un bit indiquant que les interruptions de niveau 1 sont actives |
| IEF2 | IEF2 est un bit indiquant que les interruptions de niveau 2 sont actives |
2 - Les instructions
Maintenant que nous avons vu que l'on pouvait utiliser des registres, comment les utilise-t-on ? Et d'ailleurs, comment on fait concrètement pour programmer en assembleur ? On va voir ici les quelques instructions que vous utiliserez 99% du temps.
On a vu qu'il était possible d'utiliser un certain nombre de registres dans nos programmes, qui sont en quelque sorte les variables en assembleur. Pour cela il suffit d'une instruction
ld :- Pour mettre une valeur dans un registre 8 bits ou 24 bits on fait
ld r,noù r est n'importe quel registre parmi A, B, C, D, E, H, L et BC, DE, HL et où n est un nombre entre 0 et 255 (8 bits) pour un registre 8 bits et entre 0 et 2^24 pour un registre 24 bits (ex :ld bc,12345met 12345 dans BC) - Pour mettre un registre 8 bits dans un autre registre 8 bits, on fait
ld r,r'où r et r' sont n'importe quels registres parmi A, B, C, D, E, H, L -
 Il n'est pas possible de mettre un registre 24 bits dans un autre registre 24 bits : exemple
Il n'est pas possible de mettre un registre 24 bits dans un autre registre 24 bits : exemple ld hl,deest interdit !
Les sauts et les labels
Avant de faire des If et des While like a boss, on a besoin de s'intéresser aux sauts. Mais je vous rassure, les sauts c'est vraiment pas compliqué ! Commençons par un exemple d'utilisation :
- Code: Select all
jr proche
; ...quelques instructions
proche:
jp loin
; ...
; Plein d'instructions
; ...
loin:
Pour sauter quelque part dans votre programme, il vous suffit de mettre un label à l'endroit où vous voulez sauter (ici, "proche" ou "loin" suivi du caractère deux points ':' ) et de faire soit
jp monLabel ou jr monLabel. En pratique, un label sert à donner un nom à un endroit de votre programme, un identifiant en quelque sorte. Il peut être composé des caractères lettres MAJ+min, chiffres et underscore "_". C'est bien beau tout ça mais c'est quoi la différence entre JP et JR ?
Bonne question ! Voici les avantages et inconvénients de chacun :
- JP peut sauter à n'importe quel endroit du programme et de la mémoire alors que JR ne peut sauter qu'à un label qui est 128 octets avant ou 127 octets après
- JP est légèrement plus lent que JR
- JP prend 4 octets en mémoire alors que JR n'en prend que 2
Show/Hide spoilerAfficher/Masquer le spoiler
Si vous êtes curieux, la vraie différence entre JP (JumP) et JR (Jump Relative) est que JP prend en argument une adresse (ex : jp $D1023A saute à l'adresse $D1023A) alors que JR prend en argument un offset ie une position relative (ex : jr 45 saute 45 octets plus loin). Cet offset est un entier 8 bits signé, c'est pour cela que l'on ne peut aller que 128o en arrière ou 127o en avant.
Maintenant qu'on a vu comment sauter quelque part dans notre programme, on va voir comment sauter seulement si une condition est vérifiée !
Les sauts conditionnels, les while et les if
Spoiler alert : l'assembleur ne contient ni instruction While, ni instruction If. Mais je vous rassure tout de suite : il est possible de faire des comparaisons, et donc d'en imiter le fonctionnement !
En assembleur, pour faire une comparaison, on fait
cp registre8b ou cp nombre8b. Ces deux instructions comparent, pour le premier un registre 8 bits (A B C D E H L) au registre A et pour l'autre un nombre 8 bits à A. À noter qu'il n'est pas possible de comparer des registres 24 bits de cette façon (ex : cp hl n'existe pas). Toute seule, CP ne sert pas à grand chose, elle ne fait que comparer. Il faut donc se servir du résultat pour sauter à un endroit du programme "si la condition est vérifiée". Voici par exemple comment faire un If en assembleur :- Code: Select all
cp b ; comparons A avec B
jr nz,faux ; si A!=B, on n'exécute pas le corps du IF
; et donc si on n'a pas sauté, c'est que la condition est vérifiée
faux:
; suite du programme
Peut-être que vous commencez à comprendre comment ça marche. Sinon voilà l'explication : pour faire un saut conditionnel, il faut mettre un CP puis un JP ou JR auquel on "ajoute un argument" tels que Z, NZ, C, NC (les plus utilisés). Imaginons que nous faisons
cp b, à la ligne d'après on peu mettre :jp z,labelSaute si A=Bjp nz,labelSaute si A≠Bjp c,labelSaute si A<Bjp nc,labelSaute si A≥B
C'est tout ?
Eh oui, c'est tout ! Pour l'instant ça peut paraître un peu magique mais on verra plus en détail comment ça marche lorsqu'on parlera du registre F !
En attendant, essayez de faire un If / Else, une boucle While (boucle qui s'exécute tant qu'une condition est vérifiée) et une boucle For (boucle qui s'exécute N fois) avec ce que vous avez appris. Je vous mets la réponse en spoiler mais essayez d'y réfléchir
")
Le If/Else :
Show/Hide spoilerAfficher/Masquer le spoiler
- Code: Select all
cp b
jr nz,else
; A=B
jr endif
else:
; A≠B
endif:
Le While :
Show/Hide spoilerAfficher/Masquer le spoiler
- Code: Select all
while:
cp b
jr nz,endWhile
; corps
jr while
endWhile:
Le For : (pour faire l'opération
r = r-1, on utilise l'instruction dec r ou r est n'importe quel registre)Show/Hide spoilerAfficher/Masquer le spoiler
- Code: Select all
ld a,8 ; le nombre de fois qu'on veut exécuter la boucle
for:
; corps
dec a
cp 0 ; tant que A n'est pas égal à 0, on boucle
jr nz,for
Les rageux diront que ce code n'est pas optimisé mais n'écoutez pas les rageux
Il y a bien entendu plusieurs solution et vous pouvez avoir trouvé quelque chose de différent mais qui fait quand même ce que vous voulez
Pour information, il y a un moyen beaucoup plus simple de faire un boucle For. En effet, le processeur possède une instruction 2 en 1 : DJNZ (Decrement Jump NonZero).
À noter que ce qu'utilise DJNZ est un JR, donc vous ne pourrez pas sauter plus loin que 128 octets en arrière. À noter aussi qu'après l'instruction, la valeur de B sera décrémentée de 1. Par contre la valeur de A n'est pas modifiée : A n'est donc pas mis à 0, c'est juste pour que vous compreniez comment marche l'instruction.
Il suffit alors de mettre le nombre de tours de boucle souhaités dans B, de mettre un label au début de la boucle et de mettre un DJNZ à la fin de celle-ci !
djnz label fait à elle toute seule l'équivalent de : - Code: Select all
dec b
ld a,0 ; Dans l'instruction elle-même, A n'est pas mis à 0
cp b
jr nz,label
À noter que ce qu'utilise DJNZ est un JR, donc vous ne pourrez pas sauter plus loin que 128 octets en arrière. À noter aussi qu'après l'instruction, la valeur de B sera décrémentée de 1. Par contre la valeur de A n'est pas modifiée : A n'est donc pas mis à 0, c'est juste pour que vous compreniez comment marche l'instruction.
Il suffit alors de mettre le nombre de tours de boucle souhaités dans B, de mettre un label au début de la boucle et de mettre un DJNZ à la fin de celle-ci !
Ouf, on a fini le chapitre le plus dense du tutoriel ! Prenez bien le temps d'assimiler ces notions : elles vous serviront tout le temps !
Une fois que vous êtes à peu près à l'aise avec tout ça, il est temps de passer à l'utilisation de la "vraie" mémoire : parce que 10 octets de mémoire avec les registres communs, ce n'est vraiment pas beaucoup !
3 - La mémoire
La mémoire sur ez80 est un espace linéaire de 24-bits. Bien entendu, toute cette mémoire n'est pas que de la RAM. Plus spécifiquement, sur 83PCE, le processeur est interfacé avec une puce RAM de 256Ko, ainsi que 153Ko de VRAM.
Le processeur accède au contenu de la mémoire à l'aide d'une adresse. Une adresse est juste un nombre indiquant la 'case' dans laquelle la valeur sur laquelle nous voulons travailler se trouve. La RAM se situe à l'adresse
$D00000, tandis que la VRAM se situe à l'adresse $D40000. L'adresse est dénommée pointeur.il est usuel de décrire les adresses avec leur valeur en hexadécimal. C'est plus concis et nous avons une notion plus simple de la taille des zones mémoires (100 en hexadécimal correspond à 256). Le préfixe $ permet de bien signifier au compilateur que cette valeur est en hexadécimal.
Le ez80 dispose de plusieurs moyens de travailler sur la mémoire. Nous pouvons distinguer :
- un mode d'adressage direct
- un mode d'adressage indirect
Mode d'adressage direct
Dans ce mode, nous allons donner au processeur directement la valeur du pointeur sur lequel nous travaillons. Le pointeur est fixé en dur dans le code du programme et ne peut pas être changé (sauf utilisation avancée).
Pour ce faire, il faut utiliser la syntaxe suivante de l'instruction load:
ld reg,(adresse) pour charger une valeur dans un registre ou ld (adresse),reg pour enregistrer le contenu d'un registre en mémoire. Mettre l'adresse entre parenthèses permet de signifier que nous voulons charger la valeur pointée par l'adresse et non pas la valeur absolue de l'adresse dans le registre.Il faut noter que tous les registres ne peuvent pas être utilisés par cette instruction. En registre 8 bits, seul A peut être utilisé. En registre 24 bits, HL, DE, BC, SP et les registres index IX, IY peuvent être utilisés.
Mode d'adressage indirect
Cette fois ci, au lieu de donner l'adresse au processeur, nous allons lui indiquer quel registre contient la valeur du pointeur sur la mémoire. Le processeur va lire cette valeur, chercher l'octet à cette adresse et la charger dans un registre ou copier le registre en mémoire.
Ici, c'est la syntaxe suivante de ld qui est utilisée :
ld reg,(reg) et ld (reg),reg. Nous pouvons constater l'utilisation encore présente des parenthèses.Il faut noter que tous les registres ne peuvent pas servir de destination et de pointeur. En général, le registre HL peut tout le temps servir d'adresse et de destination. DE et BC eux, ne peuvent servir d'adresse que avec A comme destination. Il convient de regarder dans la liste des instructions si la combinaison voulue existe.
Instructions de copie de bloc
Ces instructions sont très utiles si nous voulons copier des données séquentielles d'une destination vers une adresse cible. Elles peuvent copier en incrémentant les adresses à chaque fois, ou alors copier les données de manière inversée – en décrémentant les adresses.
Ces instructions sont des outils très puissants, car ils permettent de faire très rapidement un grand nombre d'actions, et ce de manière quasi-automatisée.
La première est
ldir. Elle copie l'octet présent à l'adresse contenue dans HL vers l'adresse contenue dans DE puis incrémente HL et DE. Elle décrémente ensuite BC et répète si le résultat de la décrémentation n'est pas zéro.Ainsi, si le nombre d'octets à copier doit être placé dans BC pour que cette copie soit efficace.
Il est important de considérer l'ordre du test et de la décrémentation de BC. Le test BC=0 est effectué après la décrémentation. Si la valeur de BC était zéro au début de l'instruction, celle-ci va copier 16777216 octets et va sans doute provoquer un RAM clear. BC correspond ainsi vraiment au nombre d'octet à copier.
L'autre instruction est
lddr. Elle agit de la même manière que la précédente mais HL et DE sont décrémentés au lieu d'être incrémentés.Gestion de la mémoire
La méthode précédente a le fort fâcheux désavantage de devoir mettre à chaque fois l'adresse. Celle-ci est parfois très compliquée et le programme peut travailler sur plusieurs octets de mémoire (voire même quelques milliers ou plus...). Heureusement, le compilateur permet de définir un nom pour chacune de ces zones. Plusieurs commandes peuvent réaliser ceci :
- Code: Select all
nom .equ adresse
#define nom adresse
nom:
Les deux premières sont notamment celles utilisées par l'include, si vous vous en souvenez. Cependant la troisième est particulière : il n'y pas d'adresse incluse dans la syntaxe
 C'est parce que l'adresse définie par cette syntaxe est implicite. L'adresse correspond à l'adresse que possède cette ligne dans votre programme.
C'est parce que l'adresse définie par cette syntaxe est implicite. L'adresse correspond à l'adresse que possède cette ligne dans votre programme.Ceci permet de faire un lien parfait avec les commandes suivantes, de création de zone libre de mémoire dans le programme :
- Code: Select all
.db valeur
.dl valeur
.fill size [,valeur]
.db place un octet dans le déroulement du programme ayant pour valeur celle spécifiée, tandis que .dl en place trois.Vous pouvez tenter dès à présent l'expérience suivante : placez
.db $C9 au début de votre programme de test. Vous constatez que le processeur l'interprète comme l'instruction 'RET'. Ceci est pour vous montrer que les instructions et les valeurs en mémoire forment un seul grand ensemble compris par le processeur selon l'utilisation que fait le programmeur de la mémoire.La dernière commande
.fill permet de placer size octet dans le programme à l'adresse correspondante dans le déroulement du programme. Si la valeur est spécifiée alors celle-ci est répétée, sinon, un 0 est placé.En conclusion, pour travailler sur des octets en mémoire, nous utilisons l'instruction ld. Celle-ci supporte plusieurs modes d'adressage, qui ont leur utilisation dans des contextes différents. .db et .dl permettent de placer des octets dans le programme avec une valeur définie
1 - Les flags
Les flags sont stockés dans le registre f, comme vu précédemment. Chaque flag est représenté par un bit (0/1) et permet de signifier certains événements provoqués par les instructions.
| Flag – bit - nom | Fonction |
| S – bit 7 - sign | Si la dernière instruction mathématique a rendu un résultat négatif alors, ce flag est SET. Sinon, il est RESET |
| Z – bit 6 - zero | Si le dernier calcul a causé un registre égal à zéro, alors il est SET. Sinon, il est RESET |
| H – bit 4 - half-carry | |
| P/V – bit 2 – parity/overflow | Ce flag vérifie deux conditions. Si le registre change de signe à travers une opération alors il est SET. Sinon, il est SET quand le registre possède une valeur PAIRE ou RESET quand la valeur est IMPAIRE |
| N – bit 1 – add/sub | Si la précédente opération était une soustraction alors, il est SET. Si c'était une addition alors il est RESET |
| C – bit 0 - carry | Si le résultat de la précédente opération est trop large pour tenir dans le registre de destination, alors ce flag est SET. Sinon il est RESET. |
Il est très important de noter que toutes les instructions n'affectent pas les flags de la même façon, et ceci peut-être très important dans l'exécution du programme. Il convient de vérifier dans la documentation si les flags voulus sont bien affectés par l'instruction utilisée.
Deux instructions spécifiques permettent de travailler sur le carry uniquement, fonction qui peuvent se révéler utiles pour créer des codes d'erreurs par exemple :
scf met le carry flag à 1ccf inverse le carry flagD'autres instructions peuvent être utilisées pour travailler sur les flags :
or a,a RESET le carry, tous les autres flags sont modifiés en fonctions de Axor a,a RESET le carry, SET le flag z, met le registre A à zéro.1 - Mathématique de base
Voyons maintenant comment effectuer des opérations sur les registres.
Le ez80 est un processeur 24-bits. Son ALU (ArithmeticLogicUnit) ne gère que des nombres 8 bits ou des nombres 24 bits. Il faut prendre en compte que l'ALU de la famille des ez80 est assez limitée par rapport à une unité d'un processeur moderne (x86 ou ARM).
Ainsi, celle-ci gère l'addition, la soustraction et la multiplication, ainsi que des opérations logiques sur 8 bits.
L'addition
Cette opération peut être effectuée sur 8 bits ou 24 bits. Dans les deux cas, le ez80 additionne l'accumulateur et un registre opérande et stocke le résultat dans l'accumulateur.
En 8 bits, l'accumulateur est le registre A. En 24 bits, ce sont les registres HL, IX, et IY.
La syntaxe est la suivante :
add accumulateur, opérandeIl est à noter qu'en mode 8 bits, l'opérande est un registre 8 bits, en 24 bits un registre 24 bits. Vous ne pouvez pas additionner des registres de tailles différentes. De plus, vous pouvez additioner l'accumulateur à lui même (ce qui représente une multiplication par deux de l'accumulateur).
Il existe aussi l'instruction
adc accumulateur, opérande qui ajoute l'opérande et la valeur du flag carry (cf au chapitre suivant) à l'accumulateur.L'addition normale add sur 24 bits ne modifie pas tous les flags selon leur définition. Les flags Z, P/V et S ne sont pas modifiés.
Soustraction
De la même manière, le ez80 soustrait un registre opérande à l'accumulateur et stocke le résultat dans l'accumulateur. La syntaxe est la suivante :
sub accumulateur, opérande. Cependant cette instruction n'existe que pour l'accumulateur 8 bits.Pour les registres 24 bits, seule l'instruction
sbc accumulateur, opérande existe, et l'accumulateur n'est que le registre HL. Ici, cette instruction soustrait l'opérande et la valeur du carry (comme pour adc). Pour obtenir une soustraction pure (sans l'action du carry), il faut d'abord mettre le carry à zéro :- Code: Select all
or a,a
sbc hl, reg
Ici, l'instruction logique or que nous verrons par la suite sert pour mettre la valeur du carry à zéro.
Les flags sont modifiés selon leur définition après sbc et sub.
Multiplication
Le ez80 a introduit par rapport au z80 une instruction de multiplication. La syntaxe est la suivante :
mlt reg. reg est un registre 24 bits.Cette instruction multiplie le registre bas 8 bits avec le registre haut 8 bits. Prenons un exemple pour éclaircir.
- Code: Select all
ld h, 8
ld l, 3
mlt hl
Le résultat obtenu est HL=H*L, soit 24.
Attention, le résultat de cette multiplication n'est pas signé, c'est à dire qu'il ne prend pas en compte le complément à deux. Vous devrez vous-même rajouter du code pour multiplier deux nombres signés. De plus, le registre U (le plus haut nous vous rappelons), est mis à zéro lors de l'opération.
La multiplication accepte les registres HL, DE, BC, et SP. De plus, elle n'altère pas les flags.
1 - Les routines
1 - Le stack
Le stack, pile en français, permet de stocker des données temporairement à partir notamment des registres. Elle est organisée sous la forme LIFO, Last in, first out, équivalent au dernier entré, premier sorti.
La pile utilise le registre de la pile soit SP, SPL en mode d'adressage ADL comme pointeur de la pile. Il permet de stocker l'adresse où se trouve la dernière valeur de la pile. En mode SPL, ce registre contient des adresses de 3 octets. Toute modification de ce registre induit un déplacement de la postion du stack.
Si le registre SP est utilisé comme un registre de travail, alors le stack n'est plus utilisable et toute instruction travaillant sur le stack corrompra la mémoire.
Deux instructions sont essentielles pour travailler sur la pile :
push et pop.Pour pouvoir placer des données dans la pile on utilise l'instruction push et pop pour récupérer la dernière valeur placée. Lors de l'utilisation de ces instructions, le registre SPL est affecté.
Il est décrémenté de 3 lors de l'instruction push et incréménté de 3 lors de l'instruction pop.
Le stack grandit avec des adresses décroissantes, ce qui justifie la décrémentation de l'adresse lorsqu'une nouvelle valeur est placée sur le stack.
Lors d'un travail sur le stack, il faut faire attention de bien avoir la même valeur de SP en entrée et en sortie d'une fonction ou d'un programme. Sinon, cela peut conduire à un crash.
1 - Les OS call
1 - Les ports
Les ports sont très importants en assembleur : ils permettent entre autre, de gérer la pression des touches sur le clavier, configurer l'écran, communiquer par USB avec une autre calculatrice... c'est une notion incontournable de l'assembleur ! Ces derniers servent donc à faire le lien entre les composants de la calculatrice et le programmeur. Concrètement, on va, par exemple, pouvoir dire à l'horloge de la calculatrice de changer l'heure, à l'écran de s'éteindre, au port USB d'envoyer quelque chose... tout cela grâce aux ports !
Cependant, un élément va compliquer leur utilisation sur les calculatrice eZ80. En effet, les ports des calculatrices eZ80 sont dits "memory-mapped". Pour faire court, sur les calculatrices Z80 (TI-83+/TI-84+...), les ports étaient accessibles directement et normalement grâce aux instructions
IN a,(port) pour récupérer la valeur d'un port, et OUT (port),a pour la modifier. Néanmoins, sur TI-83 Premium CE l'utilisation des instructions IN et OUT est prohibée et tenter de les utiliser ne causera soit rien, soit un RAM CLEARED. Ces restrictions sont supposées protéger et donner un sens au mode examen qui aurait pu être facilement reproduit et contourné dans le cas où un programme avait pu utiliser le port de la LED du mode examen afin d'en imiter le fonctionnement.Heureusement, il existe quand même une solution pour accéder aux ports que nous permet d'utiliser Texas Instruments. En effet, certains ports sont "mappés en mémoire" c'est-à-dire qu'ils vont pouvoir être modifiés seulement en modifiant une adresse mémoire. C'est le cas notamment pour le clavier, l'écran, les timers, l'USB... mais bien entendu pas la LED du mode examen !
Les ports sont mappés à partir de l'adresse mémoire $E00000. Par exemple, le port du clavier est mappé en mémoire à partir de l'adresse $F50000. Afin de connaître tous les ports qui peuvent être utilisés, je vous conseille de suivre ce lien vers le wikiti. Vous y trouverez tous les ports qui ont été découverts jusqu'à maintenant. Pour savoir si un port est "memory-mapped", il suffit de voir si le champ "Memory-mapped address:" existe en haut de la page décrivant le port, dans la section "Synopsis".
Afin de mieux comprendre comment cela fonctionne, nous allons aborder un exemple simple, récupérer les minutes de l'heure actuelle :
- Code: Select all
ld hl,($F30004) ; On récupère les minutes.
call _dispHL ; On affiche HL qui contient le nombre de secondes
Expliquons un petit peu. Nous voyons à cette adresse que le port "Real-Time Clock" est le port numéro $8000 et est mappé à l'adresse $F30000 en mémoire. De plus, les minutes sont stockées du port $8004 à $8007 (toutefois les minutes n'allant que de 0 à 59, seulement un octet sera utilisé sur les quatre dédiés aux minutes). L'adresse à récupérer est donc $F30004. Ensuite, on affiche les minutes avec la fonction système _dispHL qui, comme son nom le laisse présager, affiche la valeur du registre HL à l'écran.
Nous allons, en dernier lieu et partiellement, voir l'utilisation des ports les plus importants, c'est-à-dire le port du clavier et de l'écran.
Utilisation du clavier
Le clavier a une utilisation spéciale et un peu plus complexe malgré sa fréquente utilisation dans les programmes. Il nécessite quelques connaissances.
Le port du clavier a pour numéro $A000 et est mappé à l'adresse $F50000. Avant de détecter la pression des touches, nous avons besoin d'initialiser le clavier. Pour cela nous allons devoir d'abord choisir un mode pour le clavier. Il en existe quatre mais seulement trois peuvent éventuellement nous intéresser :
- Le mode "repos" : le clavier ne fait rien et ne scanne rien
- Le mode "unique scan" : le clavier est scanné une fois, puis il revient au mode "repos"
- Le mode "scan continu" : le clavier est scanné encore et encore indéfiniment...
- Code: Select all
di ; On désactive les interruptions (obligatoire)
ld hl,$F50000
ld (hl),2 ; On met le clavier en mode "un seul scan"
xor a,a
scan_wait:
cp a,(hl) ; On attend que le clavier soit retourné en mode repos ce qui voudra dire que la détection des touches est terminée
jr nz,scan_wait
; Quand la détection est terminée, on peut commencer à lire les ports
ld a,($F50012)
cp a,32 ; si la touche 2NDE a été pressée...
call z,routine
ei ; On peut réactiver les interruptions
Ici, nous avons pris l'exemple de la touche 2NDE dont l'état (enfoncée ou non) se situe à l'adresse $F50012 sur le bit 5. Pour connaître la correspondance des touches, je vous conseille de jeter un œil au tableau sur cette page. Comme on peut le voir on fait une pause (scan_wait) avant de lire le clavier, sans elle la lecture serait erronée donc ne l'oubliez pas !
Utilisation de l'écran
Le port de l'écran nécessite un chapitre entier mais nous allons aborder brièvement les bases de son utilisation. L'écran est par défaut en 16bits, c'est-à-dire qu'il y a 2^16=65536 couleurs disponibles par pixel. Chaque pixel possède une nuance de rouge, de vert et de bleu, les trois couleurs primaires en informatique. Par défaut (et je dis par défaut car il est possible de mettre l'écran en mode 8bits) chaque pixels possède donc 16 bits. Les cinq premiers bits codent pour le rouge, les six suivants pour le vert, et enfin les cinq derniers pour le bleu. On remarque que nous avons :
%0011001110010110
Maintenant, l'objectif est de savoir comment modifier la valeur d'un pixel à l'écran. Notre TI-83 Premium CE possède une vRam autrement dit une Vidéo RAM qui est un espace mémoire destiné à faire l'intermédiaire entre la mémoire et l'écran. Grosso modo, il suffit tout simplement de modifier la vRam pour que les pixels changent instantanément de couleur sur l'écran.
Nous savons que l'écran fait 320*240 pixels, avec 16 bits par pixel (=2 octets). La vRam fait donc logiquement 320*240*2, soit 153,6Ko, ce qui est énorme quand on sait que la RAM disponible à l'utilisateur fait autant !
La vRam est située à partir de l'adresse $D40000 sur 153600 octets. Prenons un exemple tout simple, on veut changer le 187ème pixel pour qu'il affiche du rose :
- Code: Select all
ld hl,%1111100000010000
ld (vRam+(186*2)),hl
À noter que comme le registre HL fait 24 bits, les 16 bits du pixel 187 seront bien modifiés, toutefois la moitié du pixel suivant (8 bits), le 188, sera mise à 0.
Il est alors possible de modifier une grande partie de l'écran grâce à un LDIR, et avec un peu de réflexion, d'afficher des sprites et des images à l'écran.
En rappel, n'oubliez pas d'aller voir le wikiti pour connaître tous les ports et leur adresse !
Voir la liste des ports connus à ce jour.
1 - Mathématique avancé
1 - Les timers
* * *
En construction
Merci à Dark_Coco pour le début du tutoriel, merci à Wistaro pour la mise en page
.
 !! C'est chouette comme tuto !!
!! C'est chouette comme tuto !! ")
